





Giải thích về kiến trúc Hopper: Từ SM đến các lệnh DPX
Hãy tìm hiểu cách những bước đột phá về kiến trúc của Hopper làm thay đổi quá trình xử lý thuật toán phức tạp.
Kiến trúc Hopper, được NVIDIA ra mắt vào tháng 3 năm 2022, đại diện cho một bước đột phá trong công nghệ GPU. Là phiên bản kế nhiệm của kiến trúc Ampere, Hopper đánh dấu bước tiến quan trọng tiếp theo của NVIDIA trong việc thúc đẩy các mô hình AI tiên tiến, mô phỏng khoa học và điện toán trung tâm dữ liệu. Được đặt tên theo Grace Hopper, một người tiên phong trong khoa học máy tính, kiến trúc GPU AI này giới thiệu những cải tiến quan trọng như bộ xử lý đa luồng (SM) được thiết kế lại, lõi Tensor thế hệ thứ tư, công cụ Transformer mạnh mẽ, hệ thống con bộ nhớ tiên tiến và các lệnh DPX mới. Những tính năng này làm cho các GPU dựa trên kiến trúc Hopper, chẳng hạn như GPU NVIDIA H100, trở nên lý tưởng cho việc huấn luyện AI quy mô lớn, điện toán hiệu năng cao (HPC) và các khối lượng công việc suy luận AI phức tạp.
Trong bài viết này, chúng ta sẽ đi sâu vào kiến trúc vi xử lý Hopper, xem xét các thành phần cốt lõi, công nghệ hướng đến hiệu năng và cách nó được tối ưu hóa cho các tác vụ AI và HPC. Chúng ta cũng sẽ khám phá những lợi ích, thách thức và ứng dụng thực tế của nó.
Kiến trúc Hopper là gì?
Hopper là kiến trúc vi xử lý GPU của NVIDIA được thiết kế đặc biệt cho các tác vụ AI và HPC. Nó cung cấp sức mạnh cho GPU NVIDIA H100 và giới thiệu nhiều cải tiến lần đầu tiên xuất hiện trong thiết kế GPU, bao gồm độ chính xác FP8, Transformer Engine và tập lệnh DPX. Hopper được xây dựng bằng quy trình TSMC 4N, một nút sản xuất 4nm tùy chỉnh tích hợp 80 tỷ bóng bán dẫn trên một khuôn duy nhất. Các từ khóa này giúp xếp hạng bài viết cho nhiều câu hỏi kỹ thuật liên quan đến kiến trúc GPU của NVIDIA và GPU hiệu năng cao.
Bộ xử lý đa luồng (SM) trong kiến trúc Hopper.
Bộ xử lý đa luồng (SM) là cốt lõi của kiến trúc GPU. Trong Hopper, các SM đã được thiết kế lại để hỗ trợ nhiều luồng hơn đáng kể và cung cấp thông lượng được cải thiện. NVIDIA H100 có tới 144 SM, mỗi SM có khả năng hỗ trợ 2.048 luồng đồng thời. Các SM này tương tự như các lõi CPU về chức năng nhưng được tối ưu hóa cho xử lý song song. Mỗi SM bao gồm:
- ALU (Bộ xử lý tín hiệu tương tự - logic thấp) dùng cho số nguyên và số thập phân.
- Đơn vị tải/lưu trữ
- Tệp đăng ký
- Bộ nhớ dùng chung/Bộ nhớ đệm L1
- Gantenser
Kiến trúc SM trong GPU Hopper cho phép xử lý đồng thời và song song ở mức cao hơn, điều cần thiết cho việc huấn luyện AI quy mô lớn và tính toán khoa học. Bộ lập lịch lệnh và hệ thống phân cấp bộ nhớ mới đảm bảo SM được sử dụng tối đa trên nhiều loại khối lượng công việc khác nhau.
Lõi Tensor và Xử lý Độ chính xác Lai
Hopper đã giới thiệu thế hệ lõi Tensor thứ tư, hỗ trợ nhiều định dạng độ chính xác khác nhau, bao gồm cả các định dạng hoàn toàn mới như FP64, FP32, FP16 và FP8. Tính linh hoạt này cho phép các mô hình AI sử dụng định dạng dữ liệu tối ưu cho từng lớp hoặc thao tác, cân bằng giữa hiệu suất và độ chính xác.
Độ chính xác FP8:
Một trong những thay đổi quan trọng nhất trong Hopper là khả năng hỗ trợ FP8, một mô hình độ chính xác thấp mới phù hợp với các tác vụ AIGPU độ chính xác cao. FP8 cho phép tính toán nhanh hơn và sử dụng bộ nhớ ít hơn so với FP16, lý tưởng cho việc huấn luyện các mô hình ngôn ngữ lớn (LLM) mà không làm giảm độ chính xác của mô hình.
Các lõi Tensor trong Hopper cung cấp:
- Quá trình huấn luyện AI nhanh hơn tới 9 lần so với A100.
- Quá trình suy luận của AI nhanh hơn tới 30 lần.
- Hiệu suất xử lý FP8 vượt quá 1.000 TFLOPS.
Động cơ biến hình
Transformer Engine là một đơn vị được thiết kế riêng trong Hopper nhằm tăng tốc các mô hình dựa trên Transformer, bao gồm GPT, BERT và T5. Nó tự động quản lý độ chính xác bằng cách sử dụng FP8 và FP16 để tối đa hóa hiệu suất mà không làm giảm chất lượng mô hình. Công cụ này có tác động đáng kể đến các mô hình xử lý ngôn ngữ tự nhiên (NLP) quy mô lớn, nơi tốc độ và hiệu quả là yếu tố quan trọng trong kiểm tra hiệu năng. Một GPU H100 sử dụng Transformer Engine có thể tạo ra các token nhanh gấp đôi so với GPU A100.
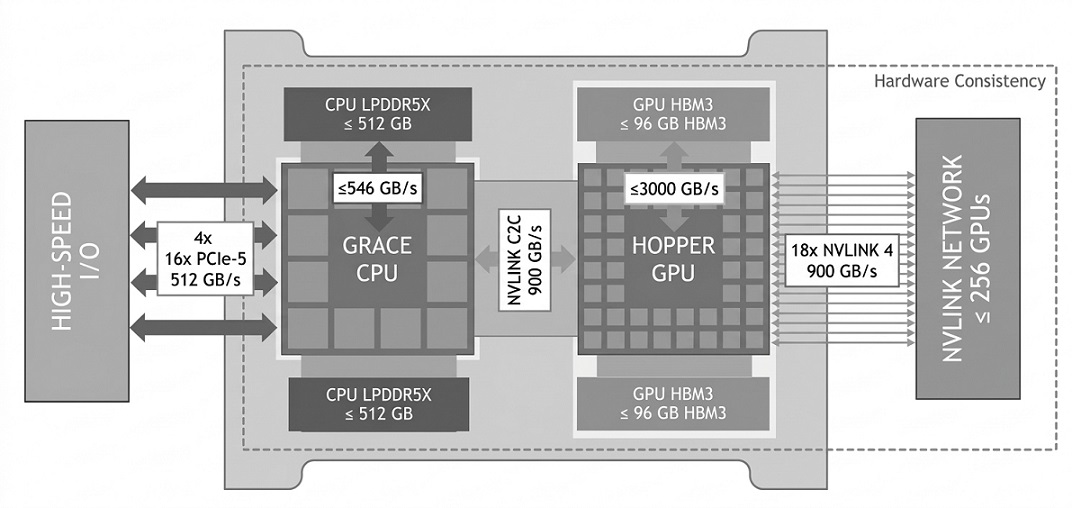
NVLink 4.0 và Kết nối GPU
Một khía cạnh cơ bản khác về hiệu năng của Hopper là NVLink 4.0. Giao tiếp thế hệ thứ tư này cho phép truyền thông cực nhanh giữa các GPU trong cấu hình đa GPU.
Các tính năng chính:
- Băng thông tối đa 900 GB/giây cho mỗi GPU.
- 18 làn NVLink, mỗi làn có tốc độ 50 GB/s.
- Cải thiện độ trễ và giảm thiểu tắc nghẽn.
NVLink 4.0 rất cần thiết để xây dựng các hệ thống siêu máy tính sử dụng hàng trăm GPU H100, đảm bảo mỗi GPU có thể chia sẻ dữ liệu một cách liền mạch, cho phép xử lý song song quy mô lớn cho việc huấn luyện mô hình AI và các tác vụ mô phỏng.
Vui lòng xem liên kết này để biết thêm thông tin về chip AI NVIDIA GB200.
MIG (GPU đa phiên bản)
GPU Hopper sở hữu công nghệ GPU đa phiên bản (MIG) thế hệ thứ hai, cho phép một GPU H100 duy nhất được phân chia thành tối đa 7 phiên bản riêng biệt, mỗi phiên bản hoạt động với các tài nguyên tính toán, bộ nhớ đệm và bộ nhớ được phân đoạn.
Những lợi ích:
- Cải thiện việc sử dụng nguồn lực.
- Tăng cường bảo mật và khả năng cách ly cho các tác vụ đám mây.
- Các cấu hình hiệu năng được tùy chỉnh cho từng người dùng khác nhau.
MIG rất phù hợp cho các trung tâm dữ liệu và các tổ chức cung cấp dịch vụ AI vì nó cho phép chia sẻ GPU một cách an toàn và hiệu quả.
Hướng dẫn DPX
Hopper đã giới thiệu DPX (Dynamic Programming Extensions) để tăng tốc các thuật toán cụ thể được sử dụng trong nhiều lĩnh vực khác nhau, chẳng hạn như:
- Hệ gen
- Phân tích đồ thị
- Tối ưu hóa chuỗi cung ứng
- Xây dựng mô hình bệnh tật.
Các lệnh DPX mới này được triển khai trong phần cứng và giảm đáng kể thời gian chạy của các thuật toán lập trình động, vốn thường tiêu tốn rất nhiều bộ nhớ và sức mạnh xử lý. Ví dụ, DPX có thể tăng tốc các thuật toán Smith-Waterman và Needleman-Wunsch được sử dụng trong tin sinh học.
Hệ thống bộ nhớ và HBM3
GPU Hopper sở hữu hệ thống bộ nhớ tiên tiến được xây dựng trên nền tảng HBM3 (High Bandwidth Memory 3). Phiên bản NVIDIA H100 GPU SXM bao gồm:
- HBM80 3 GB
- Băng thông 3,35 TB/s
Các tính năng bộ nhớ khác:
- Bộ nhớ cache L2 lớn hơn (50 MB)
- Bộ nhớ đệm L1 cho mỗi SM và bộ nhớ dùng chung.
- Băng thông cao hơn cho các tác vụ đòi hỏi nhiều bộ nhớ.
Hệ thống bộ nhớ tốc độ cao này hỗ trợ truyền dữ liệu nhanh chóng, điều cần thiết cho các tác vụ AI liên quan đến tập dữ liệu lớn.
Cấu trúc phân cấp và hệ sinh thái phần mềm CUDA.
GPU Hopper tiếp tục hỗ trợ mô hình lập trình CUDA, được phát triển để tận dụng tốt hơn những tiến bộ về kiến trúc. Các nhà phát triển CUDA có thể tận dụng:
- Thời tiền sử ở cấp độ biến dạng
- Nhóm hợp tác
- Cải thiện việc sử dụng bộ nhớ dùng chung.
NVIDIA cũng sở hữu một hệ sinh thái các thư viện và công cụ được tối ưu hóa, bao gồm:
- Vụ nổ khối lập phương.
- QDN.
- Tensor RT
- Hệ thống và quy trình xử lý Nsight.
Các công cụ này giúp các nhà phát triển gỡ lỗi, phân tích hiệu năng và tối ưu hóa các ứng dụng sử dụng nền tảng Hopper một cách hiệu quả.
Các trường hợp sử dụng và ứng dụng thực tế.
Kiến trúc Hopper phù hợp với:
- Huấn luyện các mô hình học ngôn ngữ quy mô lớn (LLM)
- Trí tuệ nhân tạo tạo sinh (Văn bản, Hình ảnh, Video)
- Học tăng cường sâu
- Mô phỏng thời tiết và khí hậu
- Khám phá thuốc và gen.
- Phát hiện gian lận theo thời gian thực trong lĩnh vực fintech.
- Đào tạo về xe tự hành.
- Khả năng tăng tốc cả quá trình suy luận và huấn luyện khiến nó trở thành một giải pháp toàn diện cho các công ty triển khai hệ thống AI quy mô lớn.
Ưu điểm và nhược điểm của kiến trúc Hopper.
Điểm nổi bật:
- Hiệu năng AI và HPC xuất sắc.
- Hỗ trợ GPU độ chính xác FP8 và Transformer Engine.
- Khả năng kết nối mạnh mẽ (NVLink 4.0)
- Khả năng mở rộng tuyệt vời với MIG (GPU đa phiên bản).
- Hướng dẫn phần cứng cụ thể (DPX)
Nhược điểm:
- Công suất tiêu thụ cao (tối đa 700W)
- đắt.
- Cần có cơ sở hạ tầng tiên tiến (hệ thống làm mát, nguồn điện, kết nối liên mạng).
Kiến trúc Hopper đã tạo nên bước đột phá trong điện toán GPU với những cải tiến như độ chính xác FP8, lõi Tensor thế hệ thứ tư, NVLink 4.0 và các lệnh DPX. Nó đã đẩy mạnh giới hạn của những gì có thể trong AI và HPC, không chỉ cung cấp tốc độ huấn luyện và suy luận nhanh hơn theo cấp số nhân mà còn cải thiện hiệu suất thông qua MIG và lập trình động tăng tốc phần cứng. Kiến trúc Hopper của NVIDIA không chỉ là một kiến trúc GPU; nó là nền tảng cho tương lai của điện toán tăng tốc.
