




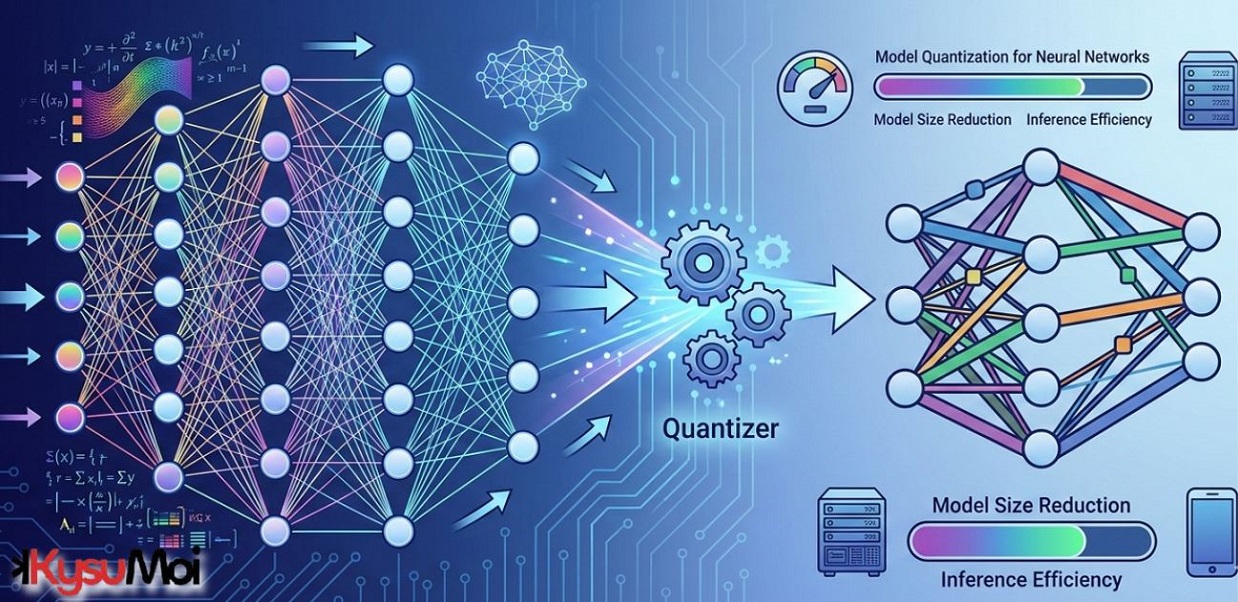
Lượng tử hóa mô hình cho mạng nơ-ron
Xem cách lượng tử hóa làm cho mạng nơ-ron nhanh hơn và nhỏ hơn mà không làm giảm hiệu suất.
Deep Learning đã cách mạng hóa các ngành công nghiệp khác nhau, dẫn đến sự phát triển liên tục của các ứng dụng kinh doanh mới. Tuy nhiên, khi các mô hình AI ngày càng phức tạp, chúng đòi hỏi nhiều bộ nhớ hơn đáng kể và hệ thống máy tính ngày càng mạnh mẽ để hoạt động hiệu quả.
Thị trường AI toàn cầu được dự báo sẽ đạt 1,85 nghìn tỷ USD vào năm 2030.
Khi AI hướng tới các thiết bị biên - thường có năng lượng, bộ nhớ và khả năng tính toán hạn chế - những hạn chế của các mạng nơ-ron hiện đại ngốn năng lượng ngày càng trở nên rõ ràng. Ngược lại, việc triển khai các mạng nơ-ron như vậy trong môi trường đám mây phát sinh chi phí điện toán đáng kể, hạn chế khả năng mở rộng và lợi nhuận của chúng cho các công ty.
Một giải pháp đầy hứa hẹn cho những thách thức này là Model Quantization. Bài viết này sẽ hướng dẫn bạn khái niệm lượng tử hóa mô hình, khám phá các loại, kỹ thuật, ưu điểm, nhược điểm của nó, v.v.
Hãy bắt đầu bằng cách hiểu lượng tử hóa mô hình và tại sao nó lại cần thiết.
Lượng tử hóa là gì?
Các nhà phát triển phải giảm kích thước của mô hình mà không làm giảm độ chính xác để triển khai mạng nơ-ron lên các thiết bị đám mây và biên một cách hiệu quả và hiệu quả. Lượng tử hóa mô hình giải quyết những thách thức này.
Để hiểu lượng tử hóa, trước tiên bạn phải hiểu các kiểu dữ liệu trong deep learning, cách chúng được chuyển đổi và biểu diễn để đạt được các mô hình có kích thước giảm, các mô hình lượng tử hóa và không lượng tử hóa khác nhau như thế nào, v.v.
Kiểu dữ liệu
Mạng nơ-ron (NN) là số dấu phẩy động được lưu trữ trong bộ nhớ của máy tính. Khi độ phức tạp của NN tăng lên, độ lớn của những con số này cũng tăng theo. Trong học sâu, float 32 bit (FP32) và float 16 bit (FP16) thường được sử dụng.
Press enter or click to view image in full size
Các định dạng dấu phẩy động cụ thể, chẳng hạn như TensorFloat (TF32) của NVIDIA, FP24 của AMD và BrainFloat (Bfloat16) của Google, cũng được thiết kế để nâng cao hiệu suất. Hơn nữa, có nhiều định dạng nhỏ hơn được gọi thông tục là minifloats (ví dụ: FP8,) tìm các ứng dụng trong bộ vi điều khiển cho các thiết bị nhúng và được hỗ trợ bởi GPU thế hệ mới như H100 của NVIDIA.
Tất cả các định dạng hoặc biểu diễn khác nhau này để lưu trữ số là rất quan trọng vì mỗi định dạng tiêu thụ một khối bộ nhớ cụ thể. Dưới đây, chúng tôi đã đề cập đến các bit (b) được phân bổ cho các biểu diễn (định dạng) khác nhau-
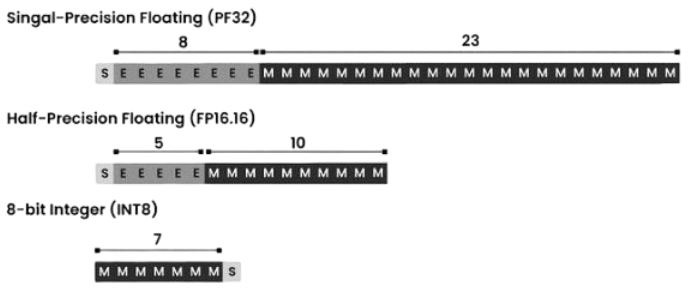
Float32 (FP32): 1b cho dấu, 8b cho số mũ, 23b cho mantissa (phân số)
Press enter or click to view image in full size

Float16 (FP16): 1b cho dấu, 5b cho số mũ, 10b cho bọ ngựa
Press enter or click to view image in full size

BF16 (B là Google Brain): 1b cho dấu, 8b cho số mũ và 7b cho mantissa
Press enter or click to view image in full size

Lượng tử hóa mô hình
Lượng tử hóa mô hình là một kỹ thuật làm giảm kích thước của các mô hình mạng nơ-ron sâu (NN) bằng cách chuyển đổi trọng số của chúng và các tham số khác từ biểu diễn dấu phẩy động có độ chính xác cao sang độ chính xác thấp hơn.
Mặc dù cách tiếp cận này mang lại những lợi ích như tăng hiệu suất mô hình, tốc độ suy luận tốt hơn, giảm yêu cầu băng thông bộ nhớ và cải thiện việc sử dụng bộ nhớ đệm, nhưng thách thức chính nằm ở việc đảm bảo rằng những cải tiến này không ảnh hưởng đến độ chính xác của mô hình.
Lượng tử hóa trong Deep Networks
Về học sâu, bạn có độ chính xác đơn hoặc đầy đủ, Float32 và độ chính xác một nửa, đề cập đến Float16 và BFloat16. Theo mặc định, độ chính xác đầy đủ được sử dụng để đào tạo và lưu trữ các mô hình học sâu và lượng tử hóa điển hình được thực hiện bằng cách chuyển đổi độ chính xác đầy đủ sang định dạng INT8. Do đó, biểu diễn INT8 thường được gọi là "lượng tử hóa".
Lượng tử hóa so với không lượng tử hóa
Sự khác biệt đáng kể có thể tồn tại giữa các mô hình lượng tử hóa và không lượng tử hóa về dấu chân bộ nhớ, tốc độ suy luận, hiệu quả và chất lượng đầu ra. Ví dụ: trong khi một mô hình không lượng tử hóa có thể chiếm khoảng 3 GB bộ nhớ, đối tác lượng tử hóa của nó có thể giảm kích thước này xuống 60–70%, giảm đáng kể mức tiêu thụ bộ nhớ.
Tương tự, một mô hình không lượng tử hóa có thể yêu cầu 40 ms cho mỗi suy luận và tiêu thụ 4 joule công suất, trong khi một mô hình lượng tử hóa có thể đạt được nhiệm vụ tương tự trong 20 ms với 2 joule, đánh dấu hiệu quả tăng 100%.
Tuy nhiên, độ chính xác có thể giảm. Ví dụ, trong NN dựa trên thị giác máy tính, một mô hình lượng tử hóa có thể tạo ra hình ảnh có chất lượng hình ảnh thấp hơn từ 8 đến 10% so với mô hình không lượng tử hóa ban đầu.
Những thách thức của lượng tử hóa mô hình
Lượng tử hóa là rất quan trọng để tối ưu hóa các mô hình máy học để triển khai trong các môi trường hạn chế về tài nguyên như thiết bị di động và điện toán biên. Bằng cách giảm độ chính xác của các thông số và hoạt động của mô hình, lượng tử hóa có thể giảm kích thước mô hình, giảm mức sử dụng bộ nhớ và tăng tốc độ suy luận. Tuy nhiên, một số thách thức có thể phát sinh, bao gồm-
1) Yêu cầu kiến thức chuyên sâu
Các mô hình khác nhau đòi hỏi các cách tiếp cận riêng biệt để lượng tử hóa và bạn phải nhận thức rõ về các kỹ thuật này. Ngoài ra, lượng tử hóa thành công thường yêu cầu các nhà phát triển phải có kiến thức trước về kiến trúc NN và thực hiện tinh chỉnh rộng rãi.
2) Độ chính xác so với hiệu quả
Cân bằng độ chính xác và kích thước mô hình, đặc biệt là với các định dạng có độ chính xác thấp như INT8, có thể khó khăn. Dải động hạn chế của chúng có thể ảnh hưởng đến độ chính xác trong quá trình chuyển đổi từ các biểu diễn có độ chính xác cao hơn.
Ví dụ: trong khi FP16 có thể thay thế FP32 với sự mất độ chính xác tối thiểu trong suy luận NN sâu, các định dạng dải động nhỏ hơn như INT8 đưa ra một thách thức đáng kể hơn. Một điều quan trọng cần nhớ là trong quá trình lượng tử hóa, việc nén dải động rộng của FP32 thành chỉ 255 giá trị của INT8, hoặc thậm chí 15 giá trị của INT4, đặt ra một thách thức đáng kể.
3) Kỹ thuật phụ trợ
Nhiều kỹ thuật bổ sung khác nhau đã được phát triển để lượng tử hóa mô hình để giải quyết những thách thức này. Chúng bao gồm tỷ lệ (mỗi kênh hoặc mỗi lớp) giúp điều chỉnh tỷ lệ và giá trị điểm không của trọng lượng và tensor kích hoạt để phù hợp hơn với định dạng lượng tử hóa.
Ngoài ra, các kỹ thuật như QAT mô phỏng quá trình lượng tử hóa trong quá trình đào tạo để chuẩn bị một mô hình lượng tử hóa. Mô phỏng này, hoặc ước tính phạm vi, được tạo điều kiện thuận lợi thông qua một quá trình được gọi là hiệu chuẩn. Hiệu chuẩn liên quan đến việc xác định các thông số hoặc điều chỉnh thích hợp để đảm bảo rằng mô hình lượng tử hóa phản ánh chặt chẽ hành vi của mô hình gốc, có độ chính xác đầy đủ.
Quy trình hiệu chuẩn khác nhau tùy theo loại mô hình và trường hợp sử dụng, với các kỹ thuật phổ biến bao gồm max, entropy, percentile, v.v. Do đó, bạn cần khám phá các kỹ thuật này ngoài việc biết các thuật toán lượng tử hóa khác nhau.
Tầm quan trọng và nhu cầu của lượng tử hóa
Mục tiêu chính của phân tích định lượng trong mạng nơ-ron (NN) là nâng cao tốc độ suy luận. Do khối lượng tuyệt đối các tham số liên quan, suy luận và đào tạo NN là những nhiệm vụ đòi hỏi nhiều tính toán.
Ví dụ: NN bao gồm các chức năng kích hoạt, trọng số và thiên vị (còn được gọi là tham số) và hàng triệu tham số như vậy có thể tồn tại trong một kiến trúc NN duy nhất.
Press enter or click to view image in full size
Hãy xem xét kiến trúc ResNet 50 lớp. Một mô hình đơn giản như vậy sẽ chứa khoảng 26 triệu trọng số và 16 triệu kích hoạt, và khi được lưu trữ bằng các giá trị dấu phẩy động 32 bit, nó sẽ tiêu tốn khoảng 168 MB bộ nhớ. Việc thực hiện các phép toán số học phức tạp trên khối lượng dữ liệu như vậy có thể cực kỳ khắt khe, đặc biệt là đối với các thiết bị biên.
Với sự ra đời của LLM (Mô hình ngôn ngữ lớn), số lượng tham số đã tăng lên đáng kể, dẫn đến sự gia tăng đáng kể về dấu chân bộ nhớ. Khi tính thực tế của NN tiếp tục tăng lên, nhu cầu triển khai chúng trên các thiết bị như điện thoại, máy tính xách tay và đồng hồ thông minh ngày càng tăng. Tuy nhiên, việc thực thi các NN phức tạp như vậy trên các thiết bị này sẽ không khả thi nếu không có lượng tử hóa.
